此货很干,跟上脚步!!!
Cookie
cookie是什么东西?
小饼干?能吃吗?
简单来说就是你第一次用账号密码访问服务器
服务器在你本机硬盘上设置一个身份识别的会员卡(cookie)
下次再去访问的时候只要亮一下你的卡片(cookie)
服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上
需求分析
爬虫要访问一些私人的数据就需要用cookie进行伪装
想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去
但是在火狐的F12截取到的数据就是,
网易云音乐先将你的账号密码给编了码,再发post请求
所以我们在准备表单数据的时候就已经被卡住了
这时候我们就可以使用自动化测试Selenium帮助我们去登录
登录好之后就获取cookie给爬虫使用
OK,废话也废话完了,直接开整吧!!
首先跟我创建一个爬虫项目和爬虫
在cmd创建
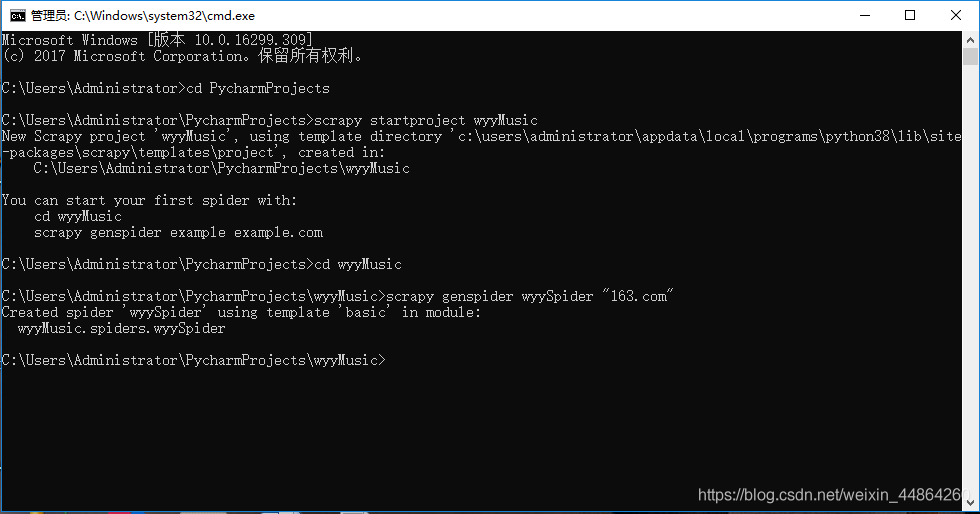
用Pycharm打开这个项目
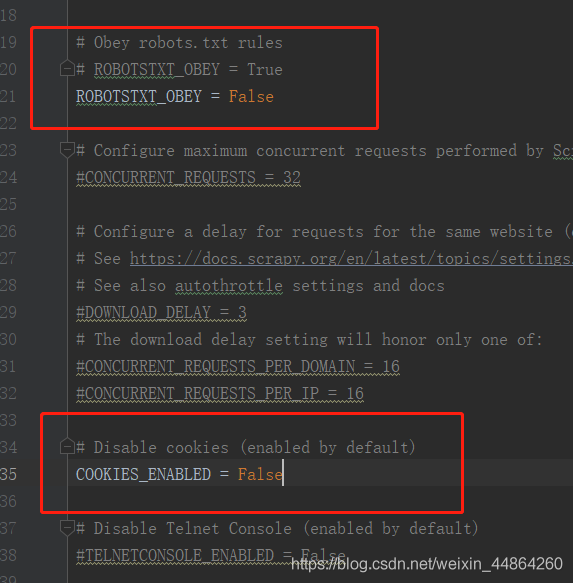
首先修改配置文件setting.py
1.关闭机器人协议
2.取消禁用cookie的功能
现在就回到爬虫文件wyySpider.py准备前期的工作
修改start_urls里的网址和准备一个请求头
首先用火狐浏览器打开网易云音乐,登录后进入到个人主页
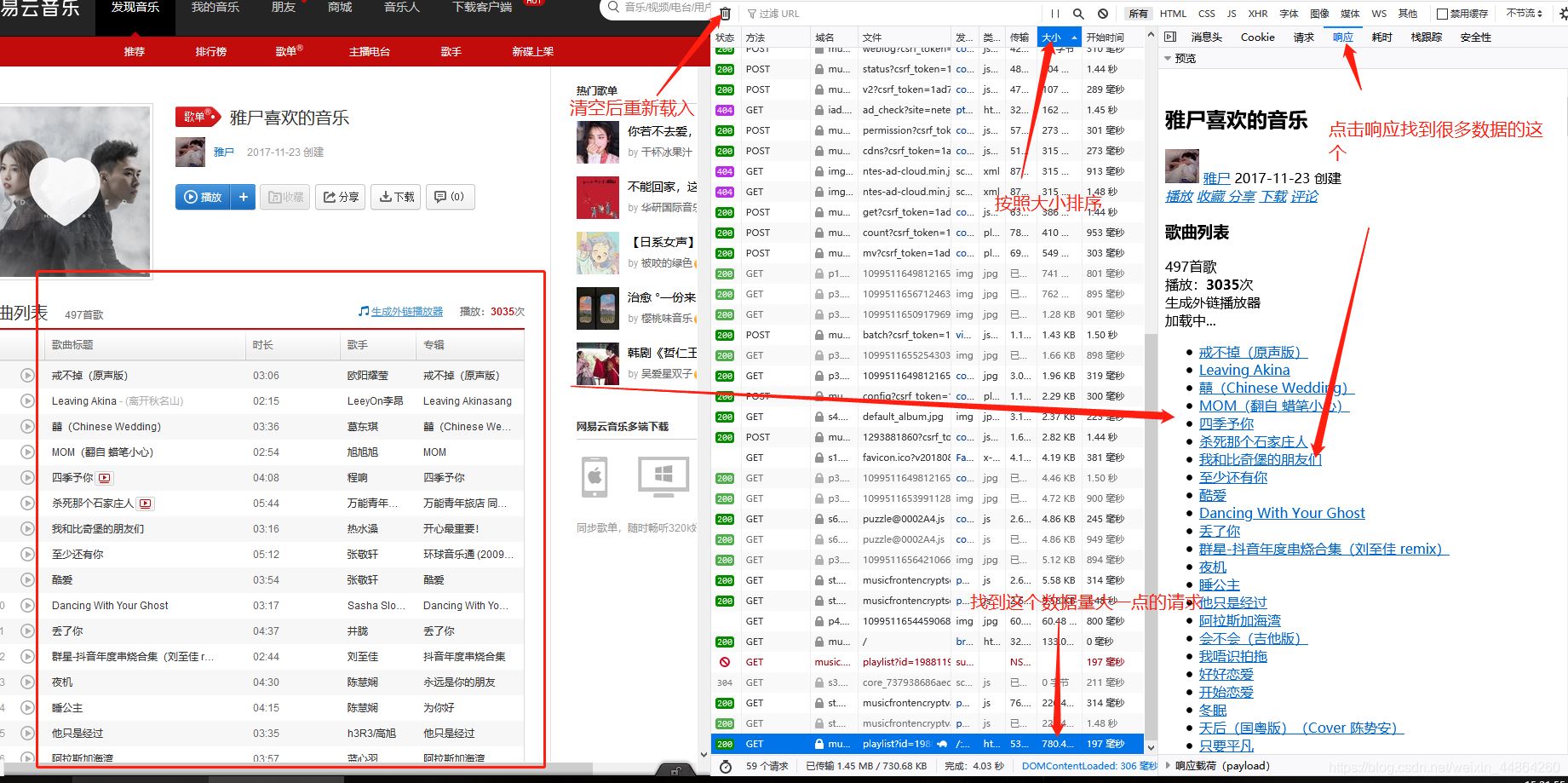
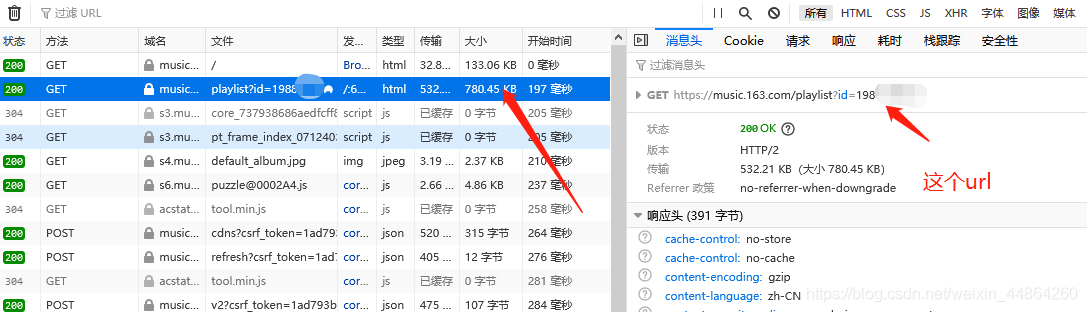
在爬虫代码那里准备一下,修改一下start_urls
import scrapy from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time class WyyspiderSpider(scrapy.Spider): name = 'wyySpider' allowed_domains = ['163.com'] start_urls = ['https://music.163.com/playlist?id=19xxxxx7']
先实现一下自动登录功能获取cookie
首先导一下自动化测试的包(Selenium)
没有这个包的话去控制台:pip --default-timeout=100 install selenium -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time
导完包还要一个谷歌的驱动程序,先看一下自己的谷歌版本
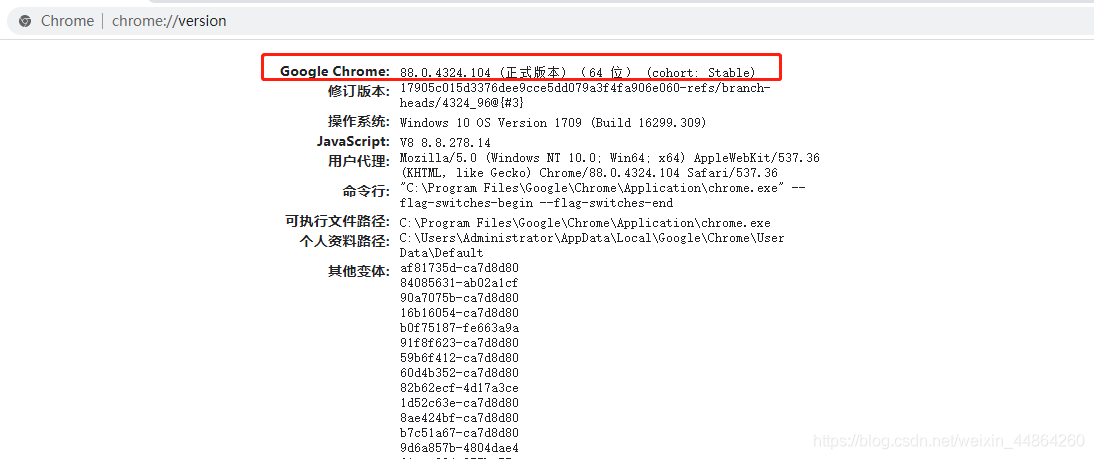
到这网站下载相同版本的驱动程序:https://sites.google.com/a/chromium.org/chromedriver/home
如果版本跟我的一样可以去网盘下载:
链接: https://pan.baidu.com/s/1M-gME2R8EEhEoFlPaDhbmA 提取码: 7iai
解压后记住这个驱动的位置,在爬虫文件写一个获取cookie的函数
以下代码的坐标不一定适合各位的电脑,不过给你们安利个物理外挂(电脑微信截图Alt+A)
def getCookie(self):
# 获取谷歌的驱动,参数为刚刚驱动程序的位置
driver = webdriver.Chrome("C:/Users/Administrator/AppData/Local/Programs/Python38/Lib/site-packages/selenium/webdriver/chrome/chromedriver.exe")
# -----------------selenium自动登录-----------------------
# 打开谷歌然后访问指定的网站
driver.get("https://music.163.com/")
# 最大化,睡眠是怕网速慢没加载出来
driver.maximize_window()
time.sleep(1)
# 鼠标从(0,0)向x(1435px),y(35px)移动,用左键点击一下
ActionChains(driver).move_by_offset(1435, 35).click().perform()
time.sleep(0.3)
# 点击其他方式
ActionChains(driver).move_by_offset(-480, 575).click().perform()
time.sleep(0.3)
# 同意条款
ActionChains(driver).move_by_offset(-218, -10).click().perform()
time.sleep(0.3)
# 手机登录
ActionChains(driver).move_by_offset(107, -100).click().perform()
time.sleep(0.3)
# 输入账号密码
# 通过css选择器获取id为"p"的标签,然后send_keys就是模拟输入一些信息
driver.find_element_by_css_selector("#p").send_keys("账号")
driver.find_element_by_css_selector("#pw").send_keys("密码")
time.sleep(0.3)
# 点击登录
ActionChains(driver).move_by_offset(110, 15).click().perform()
time.sleep(1)
# 找到头像悬浮
img = driver.find_element_by_css_selector("div.head:nth-child(1) > img:nth-child(1)")
ActionChains(driver).move_to_element(img).perform()
time.sleep(0.5)
# 点击我的主页
ActionChains(driver).move_by_offset(0, 40).click().perform()
time.sleep(0.5)
# 点击喜欢的音乐
ActionChains(driver).move_by_offset(-870, 830).click().perform()
time.sleep(0.3)
# -----------------selenium自动登录-----------------------
登录完毕后就可以获取cookie,但看一下下面的cookie
[{'domain': 'music.163.com', 'expiry': 2147483647, 'httpOnly': False, 'name': 'WM_TID', 'path': '/', 'secure': False, 'value': 'UnQj6SSNqN9BEVdubmNcEjpl%2B9DA'}, {'domain': 'music.163.com', 'expiry': 2147483647, 'httpOnly': False, 'name': 'WM_NIKE', 'path': '/', 'secure': False, 'value': '9ca17ae2e6ffcda170e2e6ee87f4508ef58483ea4a97968ea7c54e879a8eaaf445aebc83b6e933f3f1c0b4c82af0fea7c3b92af697b7a6dc7b82afc09ad98ca695bc5082ecbcb1e772b7889b3d1c15bf28da0bbfb5b95aa8795f073adbc9c98ed79a28d8aa7f450f1ae9dd9b77a85edbf9ac625f1ef84d8f970b4e7bfd8cd21b48e8c8ec17df3e7a898f74488ef9bb5c837e2a3'}, {'domain': '.music.163.com', 'httpOnly': False, 'name': 'WNMCID', 'path': '/', 'sameSite': 'Strict', 'secure': False, 'value': 'fdygqk.1611989994304.01.0'}, {'domain': '.music.163.com', 'httpOnly': False, 'name': 'WEVNSM', 'path': '/', 'sameSite': 'Strict', 'secure': False, 'value': '1.0.0'}, {'domain': 'music.163.com', 'expiry': 2147483647, 'httpOnly': False, 'name': 'WM_NI', 'path': '/', 'secure': False, 'value': '6IyEYqBqpyZMITjt9DB4tPdzuXUFC%2BNyOiu3S04CTC5Nsv2Q4gkMM0BQ2SPZxQWvItmyodTwnsbSFFqD3rS84rG3qyG%2F31L7zdp9q7N%2BpRDmBw19hwtHD1UTE%3D'}, {'domain': '.music.163.com', 'expiry': 1927349994, 'httpOnly': False, 'name': 'NMTID', 'path': '/', 'secure': False, 'value': '00O-pWx8ZDJJQfiFkHzsgin07nYSmUAAAF3UhdN2w'}, {'domain': '.163.com', 'expiry': 4765589994, 'httpOnly': False, 'name': '_ntes_nuid', 'path': '/', 'secure': False, 'value': '738fc9cd89d6d8799fa76b3348d25d7d'}, {'domain': '.163.com', 'expiry': 4765589994, 'httpOnly': False, 'name': '_ntes_nnid', 'path': '/', 'secure': False, 'value': '738fc9cd89d6d8799fa76b3348d25d7d,1611989994150'}, {'domain': '.music.163.com', 'expiry': 1769671794, 'httpOnly': False, 'name': '_iuqxldmzr_', 'path': '/', 'secure': False, 'value': '32'}, {'domain': '.music.163.com', 'expiry': 1769671794, 'httpOnly': False, 'name': 'JSESSIONID-WYYY', 'path': '/', 'secure': False, 'value': 'OoCMxNwGV%5CfZD2OSzAXovf4ASVZsJ8UQ4sgg7JfH075cKTD%2FW3sMzZj%2BpayS1EnNVXzRm%2F2GxfzIoNv3FTjYxKeNFZWqf6UeiMSc1%2BG98kgsEM94juuE%5Cs18k2%2BPNPAp3hU0G%5CFDUtjkimCR5pgOIOI%3A1611991794102'}]
是列表加字典的结构,而Scrapy的cookie是字符串类型的,所以我们要做一个转型
# 将driver获取的字典类型的cookie提取name和value封装成字符串
temp = []
for i in driver.get_cookies():
temp.append(i['name'] + "=" + i['value'])
# 返回字符串cookie
return ';'.join(temp)
所以这个函数基本就写完了,自动登录后获取cookie是不是很爽!!!
现在重写一下def start_requests(self),这个函数是在请求发起前执行的
在这个函数把请求头给塞进去,因为setting那边没有定义
def start_requests(self):
# 定义请求头的时候调用一下getCookie获取一下cookie
headers = {
'Cookie': self.getCookie(),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# 注意url是个列表这里拿下标[0],然后把headers请求头塞进去,交给parse函数
yield scrapy.Request(url=self.start_urls[0], headers=headers, callback=self.parse)
请求前一切准备好之后,在解析函数(parse)进行保存一下数据,记得导re包
def parse(self, response):
# 匹配歌曲名的正则表达式
patt = re.compile(r'<a href="/song.id=.*?">([^<|{]*?)</a>')
# 找到所有歌曲名
listdata = re.findall(patt, response.text)
# 把数据写进txt文件
with open(file="../response.txt", mode="w+", encoding="utf-8") as file:
for item in listdata:
file.write(item+"\n")
一句启动爬虫的命令,眨眨眼的时间 ~
数据就进去了哦!原来我的喜爱歌单只有不到500~
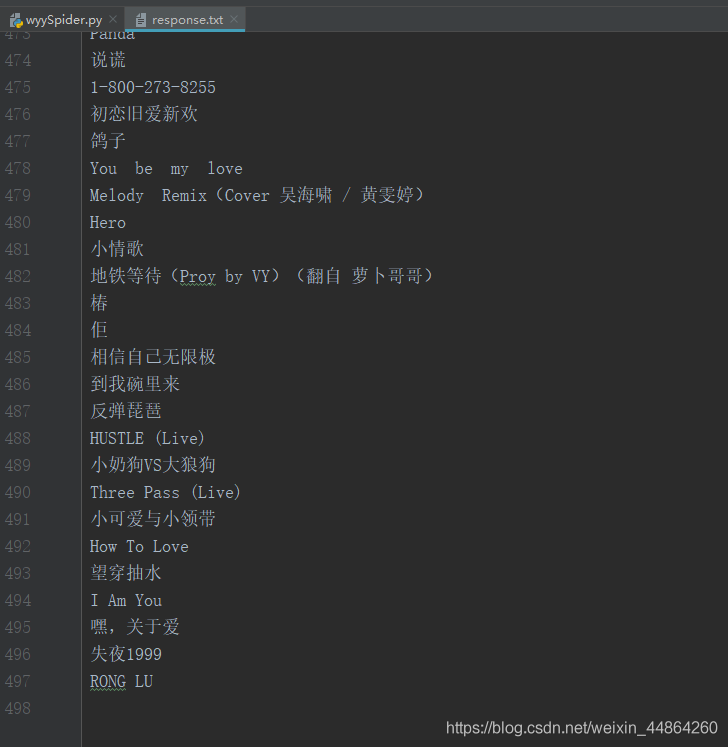
下面就是爬虫源代码
import scrapy
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
import re
class WyyspiderSpider(scrapy.Spider):
name = 'wyySpider'
allowed_domains = ['163.com']
start_urls = ['https://music.163.com/playlist?id=19xxxxx7']
def getCookie(self):
# 获取谷歌的驱动,参数为刚刚驱动程序的位置
driver = webdriver.Chrome("C:/Users/Administrator/AppData/Local/Programs/Python38/Lib/site-packages/selenium/webdriver/chrome/chromedriver.exe")
# -----------------selenium自动登录-----------------------
# 打开谷歌然后访问指定的网站
driver.get("https://music.163.com/")
# 最大化,睡眠是怕网速慢没加载出来
driver.maximize_window()
time.sleep(1)
# 以下坐标以自己的电脑为准
# 鼠标从(0,0)向x(1435px),y(35px)移动,用左键点击一下
ActionChains(driver).move_by_offset(1435, 35).click().perform()
time.sleep(0.3)
# 点击其他方式
ActionChains(driver).move_by_offset(-480, 575).click().perform()
time.sleep(0.3)
# 同意条款
ActionChains(driver).move_by_offset(-218, -10).click().perform()
time.sleep(0.3)
# 手机登录
ActionChains(driver).move_by_offset(107, -100).click().perform()
time.sleep(0.3)
# 输入账号密码
# 通过css选择器获取id为"p"的标签,然后send_keys就是模拟输入一些信息
driver.find_element_by_css_selector("#p").send_keys("账号")
driver.find_element_by_css_selector("#pw").send_keys("密码")
time.sleep(0.3)
# 点击登录
ActionChains(driver).move_by_offset(110, 15).click().perform()
time.sleep(1)
# 找到头像悬浮
img = driver.find_element_by_css_selector("div.head:nth-child(1) > img:nth-child(1)")
ActionChains(driver).move_to_element(img).perform()
time.sleep(0.5)
# 点击我的主页
ActionChains(driver).move_by_offset(0, 40).click().perform()
time.sleep(0.5)
# # 点击喜欢的音乐
# ActionChains(driver).move_by_offset(-870, 830).click().perform()
# time.sleep(0.3)
# -----------------selenium自动登录-----------------------
# 将driver获取的字典类型的cookie提取name和value封装成字符串
# 临时存放每个拼接好的key=value字符串
temp = []
# 遍历driver给的cookies字典
for i in driver.get_cookies():
temp.append(i['name'] + "=" + i['value'])
# 返回字符串cookie
return ';'.join(temp)
def start_requests(self):
# 定义请求头的时候调用一下getCookie获取一下cookie
headers = {
'Cookie': self.getCookie(),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# 注意url是个列表这里拿下标[0],然后把headers请求头塞进去,交给parse函数
yield scrapy.Request(url=self.start_urls[0], headers=headers, callback=self.parse)
def parse(self, response):
# 匹配歌曲名的正则表达式
patt = re.compile(r'<a href="/song.id=.*?">([^<|{]*?)</a>')
# 找到所有歌曲名
listdata = re.findall(patt, response.text)
# 把数据写进txt文件
with open(file="response.txt", mode="w+", encoding="utf-8") as file:
for item in listdata:
file.write(item+"\n")
到此这篇关于Scrapy+Selenium自动获取cookie爬取网易云音乐个人喜爱歌单的文章就介绍到这了,更多相关Scrapy+Selenium爬取网易云音乐内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



