我们在使用Django的models查询数据库时,可以看到有这种写法:
form app.models import XXX query = XXX.objects.all() query = query.filter(name=123, age=456).filter(salary=999)
在这种写法里面,query对象有一个filter方法,这个方法的返回数据还可以继续调用filter方法,可以这样无限制地调用下去。
这种写法是怎么实现的呢?
如果我们直接写一个类的方法,看看能不能这样调用:
class Query: def filter(self): pass query = Query() query.filter().filter()
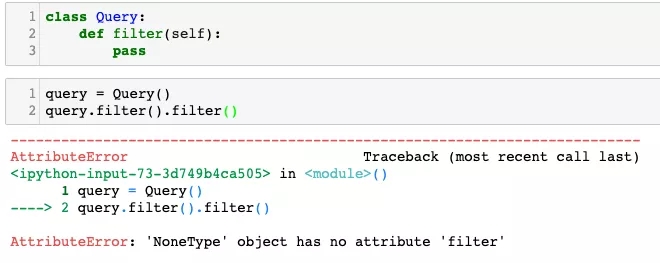
直接对query.filter()返回的结果再调用一次filter,就会导致报错了。这是因为在没有显式写return语句的时候,方法会返回None,而None对象是没有所谓的filter方法的。
那么什么东西有filter方法呢?显然我们的query对象有filter方法。那么如何让这个方法返回自身这个对象呢?
这个时候,我们就要看看我们在定义类方法的时候,总会写的的第一个参数self了。几乎每个类方法里面都会有它。大家只知道在类里面调用类方法的时候可以用self.xxx(),在调用类属性的时候可以用self.yy,那么有没有思考过,这个东西如果单独使用会怎么样呢?
实际上,self指的就是这个类实例化成一个对象以后,这个对象自身。而这个对象显然是有filter方法的。所以我们修改一下filter方法,让它返回self:
class Query: def filter(self): return self query = Query() query.filter().filter()
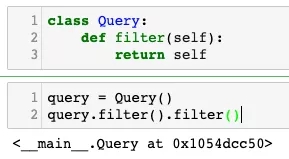
从图中可以看出,现在已经不会报错了。那么回到最开始的问题,Django里面的链式调用传入查询参数是如何实现的呢?
实际上这里涉及到一个惰性查询的问题。
当我们不停调用.filter()方法的时候,Django会把这些查询条件全部缓存起来,只有当我们需要获取结果,或者查询满足条件的数据有多少条时,它才会真正地连接数据库去查询。
所以我们这里要模拟这个环境,把查询条件缓存起来。
那么为了获取调用方法时传入的参数名,我们就要使用**kwargs参数。这个参数可以接受所有的key=value形式的参数:
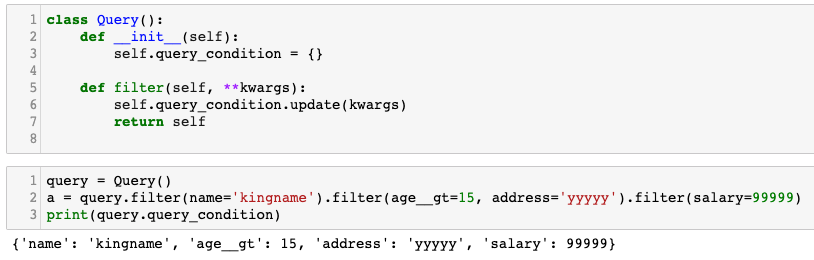
class Query():
def __init__(self):
self.query_condition = {}
def filter(self, **kwargs):
self.query_condition.update(kwargs)
return self
query = Query()
a = query.filter(name='kingname').filter(age__gt=15, address='yyyyyy').filter(salary=99999)
print(query.query_condition)
运行效果如下图所示:
在真正需要输出结果的时候,再使用这些缓存的条件,去数据库中查询结果即可。
以上就是python中如何实现链式调用的详细内容,更多关于python 实现链式调用的资料请关注其它相关文章!



