使用pycharm批量爬取小说
爬取小说的思路:
1.获取小说地址
本文以搜书网一小说为例《嘘,梁上有王妃!》
目录网址:https://www.soshuw.com/XuLiangShangYouWangFei/
加载需要的包:
import re from bs4 import BeautifulSoup as ds import requests
获取小说目录文件,返回<Response [200]>,表示可正常爬取该网页
base_url='https://www.soshuw.com/XuLiangShangYouWangFei/' chapter_html=requests.get(base_url) print(chapter_html)
2.分析小说地址结构
解析目录网页 , 输出结果为目录网页的源代码
chapter_page_html=ds(chapter_page,'lxml') print(chapter_page)
打开目录网页,发现在正文的目录前面有一个最新章节目录(这里有九个章节),再完整的目录中是包含最新章节的,所以这里最新章节是不需要的。
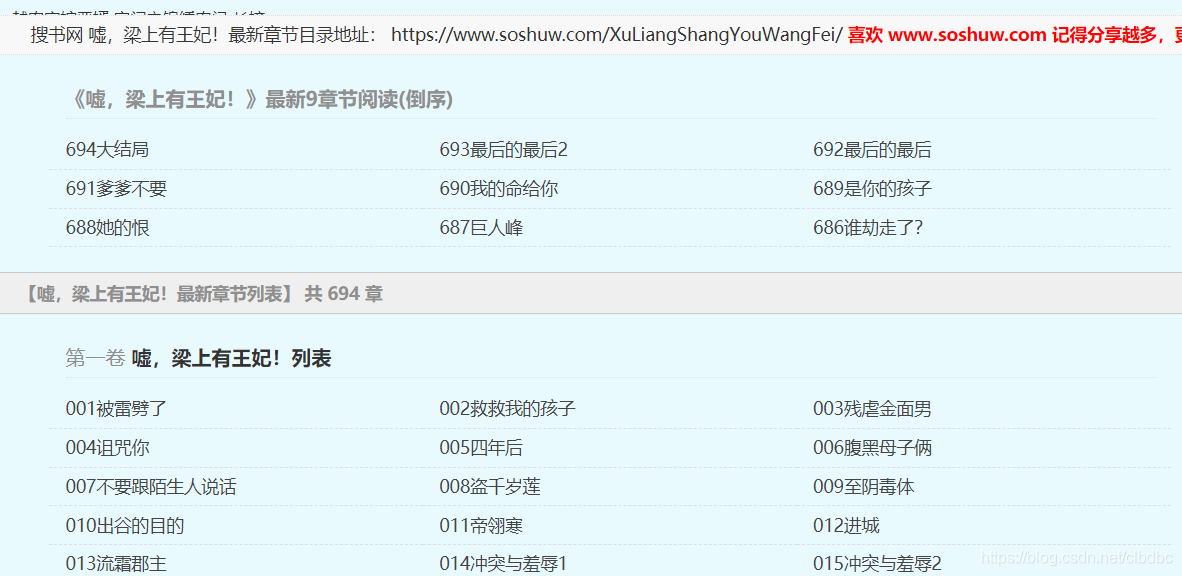
在网页单击右键选择“检查”(或者“属性”,不同的浏览器的叫法不一致,我用的是IE)选择“元素”列,鼠标再右侧代码块上移动时。左侧网页会高亮显示其对应网页区域,找到完整目录对应的代码块。如下图:

完整目录的锚有两个,分别是class="novel_list"和id=“novel108799”,仔细观察后发现class不唯一,所以我们选用id提取该块内容

将完整目录块提取出来
chapter_novel=chapter_page.find(id="novel108799") print(chapter_novel)
结果如下(仅部分结果):

对比小说章节内容网址和目录网址(base_url)发现,我们只需要将base_url和章节内容网址的后半段拼接到一起就可以得到完整的章节内容网址
3.拼接地址
利用正则语言库将地址后半段提取出来
chapter_novel_str=str(chapter_novel) regx = '<dd><a href="/XuLiangShangYouWangFei(.*?)"' chapter_href_list = re.findall(regx, chapter_novel_str) print(chapter_href_list)
拼接url:
定义一个列表chapter_url_list接收完整地址
chapter_url_list = [] for i in chapter_href_list: url=base_url+i chapter_url_list.append(url) print(chapter_url_list)
4.分析章节内容结构
打开章节,右键→“属性”,查看内容结构,发现小说正文有class和id两个锚,class是不变的,id随着章节而变化,所以我们用class提取正文

提取正文段
chapter_novel=chapter_page.find(id="novel108799") print(chapter_novel)
提取正文文本和标题
body_html=requests.get('https://www.soshuw.com/XuLiangShangYouWangFei/3647144.html')
body_page=ds(body_html.content,'lxml')
body = body_page.find(class_='content')
body_content=str(body)
print(body_content)
body_regx='<br/> (.*?)\n'
content_list=re.findall(body_regx,body_content)
print(content_list)
title_regx = '<h1>(.*?)</h1>'
title = re.findall(title_regx, body_html.text)
print(title)
5.保存文本
with open('1.txt', 'a+') as f:
f.write('\n\n')
f.write(title[0] + '\n')
f.write('\n\n')
for e in content_list:
f.write(e + '\n')
print('{} 爬取完毕'.format(title[0]))
6.完整代码
import re
from bs4 import BeautifulSoup as ds
import requests
base_url='https://www.soshuw.com/XuLiangShangYouWangFei'
chapter_html=requests.get(base_url)
chapter_page=ds(chapter_html.content,'lxml')
chapter_novel=chapter_page.find(id="novel108799")
#print(chapter_novel)
chapter_novel_str=str(chapter_novel)
regx = '<dd><a href="/XuLiangShangYouWangFei(.*?)"'
chapter_href_list = re.findall(regx, chapter_novel_str)
#print(chapter_href_list)
chapter_url_list = []
for i in chapter_href_list:
url=base_url+i
chapter_url_list.append(url)
#print(chapter_url_list)
for u in chapter_url_list:
body_html=requests.get(u)
body_page=ds(body_html.content,'lxml')
body = body_page.find(class_='content')
body_content=str(body)
# print(body_content)
body_regx='<br/> (.*?)\n'
content_list=re.findall(body_regx,body_content)
#print(content_list)
title_regx = '<h1>(.*?)</h1>'
title = re.findall(title_regx, body_html.text)
#print(title)
with open('1.txt', 'a+') as f:
f.write('\n\n')
f.write(title[0] + '\n')
f.write('\n\n')
for e in content_list:
f.write(e + '\n')
print('{} 爬取完毕'.format(title[0]))
到此这篇关于使用PyCharm批量爬取小说的文章就介绍到这了,更多相关PyCharm批量爬取小说内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



