1、打开文件
open()函数简介 :
打开文件使用open函数,可以打开一个已经存在的文件,如果没有这个文件的话,会创建一个新文件
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:(一般只会用到前三个) file: 必需,文件路径(相对或者绝对路径)。 mode: 可选,文件打开模式 encoding: 一般使用utf8 buffering: 设置缓冲 errors: 报错级别 newline: 区分换行符 closefd: 传入的file参数类型 opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
- mode模式
'''
文件打开模式
r 以只读方式打开文件,文件的指针将会放在文件的开头,这是默认模式。
w 打开一个文件只用于写入。如果该文件已经存在则将其覆盖,如果不存在,创建新文件。
r+ 打开一个文件用于读写,文件指针将会被放在文件的开头。
w+ 打开一个文件用于读写。如果该文件已经存在则将其覆盖,如果不存在,创建新文件。
rb+ 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
wb+ 以二进制格式打开一个文件用于读写。如果该文件已经存在则将其覆盖,如果不存在,创建新文件。
a 打开一个文件用于追加,如果文件已经存在,文件指针将会放在文件的结尾,也就是说,新的内容将会被写到已有内容之后。
如果文件不存在,创建新的文件进行写入。
'''
- encoding编码类型
encoding一般默认是gbk,为中文编码,但通常都是以utf-8写入和读取最好在打开文件时指定编码类型
打开文件,没有的话自动创建一个文件
File1_Object = open('Text1.txt', 'w', encoding='utf-8') # 返会一个文件对象赋值给File1_Object
此时左边工程栏会出现一个文件
2、写入
默认形式写入
File1_Object = open('Text1.txt', 'w', encoding='utf-8')
File1_Object.write('始知相忆深\n') # 往该对象里写入内容
File1_Object.write('直道相思了无益,未妨惆怅是清狂\n')
File1_Object.close() # 保存并关闭
此时打开文件,会有以下内容

以二进制的形式打开并写入
File2_Object = open('Text2.txt', 'wb')
File2_Object.write('我喜欢的人要心若明镜,眼若星辰,便是看尽人间丑恶,也依然心怀善良,优雅从容!\n'.encode('utf-8'))
# .encode('utf-8') str->bytes
# 不加的话会报错 TypeError: a bytes-like object is required, not 'str'
File2_Object.close()

注意,以二进制形式操作文件,不管是写入和读取都不加encoding,否则会报错
如果加encoding='utf-8'的话,会有以下错误显示:

不加encoding的情况
# 后面不加encoding='utf-8',默认为gbk
File5_Object = open('Text3.txt', 'w')
File5_Object.write('将头发梳成大人摸样\n')
File5_Object.write('换上一身帅气西装\n')
File5_Object.write('等回来见你一定比想象美\n')
File5_Object.close()

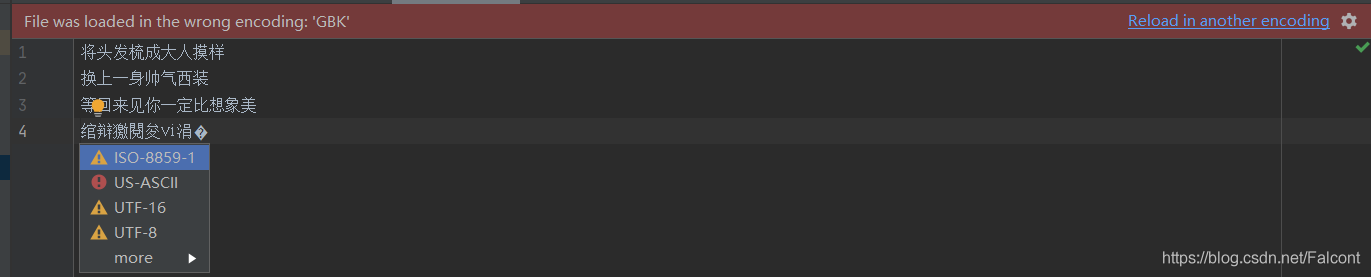
此时打开Text3会有以下显示:

点击箭头指向位置,将会显示出内容:

3、追加
一般追加形式
File3_Object = open('Text1.txt', 'a', encoding='utf-8')
File3_Object.write('我喜欢的人要心若明镜,眼若星辰,便是看尽人间丑恶,也依然心怀善良,优雅从容!\n')
File3_Object.close()
此时Text1里面的内容为:

对Text2进行追加:
File2_Object = open('Text2.txt', mode='ab')
File2_Object.write('处处相思苦!'.encode('utf-8'))
File2_Object.close()

对Text3进行追加
如果此时加了encoding=‘uft-8'
File5_Object = open('Text3.txt', 'a', encoding='utf-8')
File5_Object.write('纱窗醉梦中')
File5_Object.close()
打开文件Text3

仍会显示异常,此时需点击箭头指向位置,会显示:
点击utf-8的话会显示:
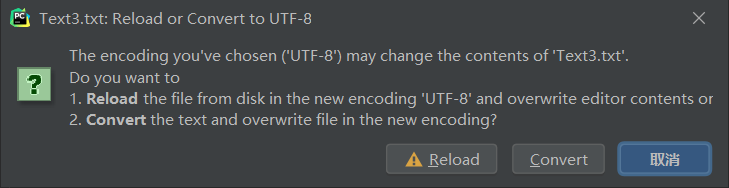
所以当文件第一次打开写入时没有加encoding时,后续进行操作也不要加,不然会有乱码,加了encoding的话,编码格式后续也不要改变。
此时删掉encoding=‘utf-8',文件内容为正常
File5_Object = open('Text3.txt', 'a')
File5_Object.write('纱窗醉梦中')
File5_Object.close()

4、读文件
read(),将文件的内容全部读取出来。
File4_Object = open('Text1.txt', 'r', encoding='utf-8')
print(File4_Object.read())
File4_Object.close()

read(num),传入一个参数,表示读取指定字符个数
File4_Object = open('Text1.txt', 'r', encoding='utf-8')
print(File4_Object.read(4)) # 只读取前四个字符
print(File4_Object.read()) # 第二次读取将从上一次读取的位置继续读取
File4_Object.close()
print()

readline() 一次性读一行
File4_Object = open('Text3.txt', 'r')
print(File4_Object.readline())
print(File4_Object.readline()) # 第二次读取将从第二行开始
print(File4_Object.readline())
File4_Object.close()

readlines() 按行读取,一次性读取所有内容,返回一个列表,每一行内容作为一个元素
File5_Object = open('Text3.txt', mode='r')
print(File5_Object.readlines())
File5_Object.close()

以二进制形式读文件
File5_Object = open('Text2.txt', 'rb')
content = File5_Object.read()
print(content.decode('utf-8')) # decode解码
# 由于原来Text2文件时以二进制形式打开并写入的,此时解码就直接用utf-8,不能用gbk
File5_Object.close()
File5_Object = open('Text3.txt', 'rb')
content = File5_Object.readline() # 只读取一行
print(content.decode('gbk'))
# 而Text3第一次创建并写入时是以默认gbk的形式写入的,此时只能用gbk解码
File5_Object.close()

with上下文管理对象,可以自动释放打开的对象,防止忘记close()操作
with open('Text2.txt', 'r', encoding='utf-8')as File5_Object:
print(File5_Object.read())

5、文件拷贝
小文件
def Copy_File():
# 接收用户输入的文件名
Original_File = input('请输入要备份的文件名:')
New_File_Name = Original_File.split('.') #分割接收到的文件名
New_File = New_File_Name[0] + '_copy.' + New_File_Name[1]
Original_File_Object = open(Original_File, mode='r', encoding='utf-8') # 以只读的模式打开之前的文件
New_File_Object = open(New_File, mode='w', encoding='utf-8') # 以写入的方式打开新备份的文件
New_File_Object.write(Original_File_Object.read())
Original_File_Object.close()
New_File_Object.close()
pass
Copy_File()
New_File = open('Text_copy.txt', mode='r', encoding='utf-8')
print(New_File.readlines())
New_File.close()
大文件
def Copy_Big_File():
# 接收用户输入的文件名
Original_File = input('请输入要备份的文件名:')
New_File_Name = Original_File.split('.') #分割接收到的文件名
New_File = New_File_Name[0] + '_copy.' + New_File_Name[1]
try:
with open(Original_File, mode='r', encoding='utf-8')as Original_File_Object, open(New_File, mode='r', encoding='utf-8')as New_File_Object:
while True:
connect = Original_File_Object.read(1024)
New_File_Object.read(connect)
if len(connect) < 1024:
break
pass
pass
pass
pass
except Exception as msg:
print(msg)
pass
pass
Copy_Big_File()
6、tell()
文件定位,指的是当前文件指针读取到的位置,光标位置。在读写文件的过程中,如果想知道当前的位置,可以使用tell()来获取
File_Object = open('Text1.txt', mode='r', encoding='utf-8')
print(File_Object.read(2))
print(File_Object.tell())
print(File_Object.read(5))
print(File_Object.tell())
File_Object.close()
# utf-8编码格式中每个汉字占3个字节
print()

注解:先读取两个汉字,print输出 “始知”,此时光标位置为6说明utf-8编码格式中每个汉字占3个字节,之后再读取5个,而只显示了相忆深并换行打印了直,是因为还有一个换行符,此时光标定位到20,又能说明转义符在utf-8编码格式中占2个字节。
7、truncate(size)
可以对源文件进行截取操作,截取size字节大小数据,截取之后源文件将被修改,里面只剩下截取的数据
File_Object = open('Text1.txt', mode='r', encoding='utf-8')
print('截取之前文件里的内容:')
print(File_Object.read())
File_Object.close()
File_Object = open('Text1.txt', mode='r+', encoding='utf-8')
# r+ 打开一个文件用于读写。文件指针将会放在文件的开头。
print()
File_Object.truncate(12) # 执行完此行代码后源文件会被修改
print(File_Object.tell())
print('截取之后文件里的内容:')
print(File_Object.read())
print(File_Object.tell())
File_Object.close()
print()
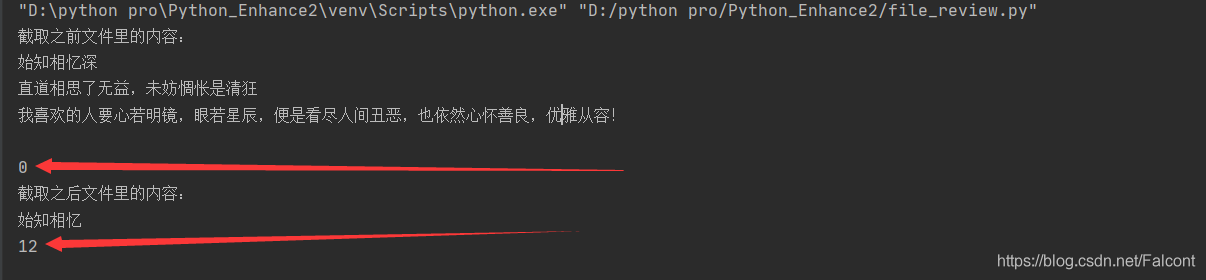
光标第一次位置指向开头(r+),截取之后(12个字节),指向文件末尾12
- 截取之前Text1为以下内容

- 截取后为

8、seek()
在操作文件的过程,可定位到其他位置进行操作 seek(offset,from)有2个参数,offset指偏移字节量,负数是往前偏移,正数是往后偏移。from位置,0表示文件开头,1表示当前位置,2表示文件末尾
File_Object = open('Text1.txt', mode='rb')
print(File_Object.read(15).decode('utf-8'))
print(File_Object.tell()) File_Object.seek(-6, 1)
print(File_Object.tell())
print(File_Object.read(6).decode('utf-8')) File_Object.close()
''' 使用seek()函数时,有时候会报错为 “io.UnsupportedOperation: can't do
nonzero cur-relative seeks”
照理说,按照seek()方法的格式file.seek(offset,whence),后面的1代表从当前位置开始算起进行偏移,那又为什么报错呢?
这是因为,在文本文件中,没有使用b模式选项打开的文件,只允许从文件头开始计算相对位置,从文件尾计算时就会引发异常。 将
f=open("aaa.txt","r+") 改成 f = open("aaa.txt","rb") 就可以了 '''
对于文件操作更系统实战的操作,读者可参考
https://www.jb51.net/article/149035.htm
读者可根据里面的流程分析对基础进行巩固。
到此这篇关于python基础之文件操作的文章就介绍到这了,更多相关python文件操作内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



