Scrapy下载图片项目介绍
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求。
使用Scrapy下载图片
项目创建
首先在终端创建项目
# win4000为项目名 $ scrapy startproject win4000
该命令将创建下述项目目录。
项目预览
查看项目目录
- win4000
- win4000
- spiders
- __init__.py
- __init__.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
- scrapy.cfg
创建爬虫文件
进入spiders文件夹,根据模板文件创建爬虫文件
$ cd win4000/win4000/spiders # pictures 为 爬虫名 $ scrapy genspider pictures "win4000.com"
项目组件介绍
1.引擎(Scrapy):核心组件,处理系统的数据流处理,触发事务。
2.调度器(Scheduler):用来接受引擎发出的请求, 压入队列中, 并在引擎再次请求的时候返回。由URL组成的优先队列, 由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
3.下载器(Downloader):用于下载网页内容, 并将网页内容返回给Spiders。
4.爬虫(Spiders):用于从特定的网页中提取自己需要的信息, 并用于构建实体(Item),也可以从中提取出链接,让Scrapy继续抓取下一个页面
5.管道(Pipeline):负责处理Spiders从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被Spiders解析后,将被发送到项目管道。
6.下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7.爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理Spiders的响应输入和请求输出。
8.调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy爬虫流程介绍
Scrapy基本爬取流程可以描述为UR2IM(URL-Request-Response-Item-More URL):
1.引擎从调度器中取出一个链接(URL)用于接下来的抓取;
2.引擎把URL封装成一个请求(Request)传给下载器;
3.下载器把资源下载下来,并封装成应答包(Response);
4.爬虫解析Response;
5.解析出实体(Item),则交给实体管道进行进一步的处理;
6.解析出的是链接(URL),则把URL交给调度器等待抓取。
页面结构分析
首先查看目标页面,可以看到包含多个主题,选取感兴趣主题,本项目以“风景”为例(作为练习,也可以通过简单修改,来爬取所有模块内图片)。
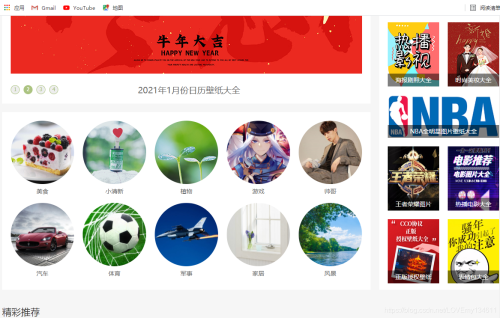
在“风景”分类页面,可以看到每页包含多个专题,利用开发者工具,可以查看每个专题的URL,拷贝相应XPath,利用Xpath的规律性,构建循环,用于爬取每个专题内容。
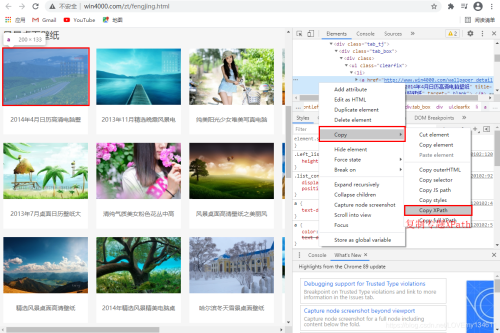
# 查看不同专题的XPath # /html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li[1]/a # /html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li[2]/a
利用上述结果,可以看到li[index]中index为专题序列。因此可以构建Xpath列表如下:
item_selector = response.xpath('/html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li/a/@href')
利用开发者工具,可以查看下一页的URL,拷贝相应XPath用于爬取下一页内容。
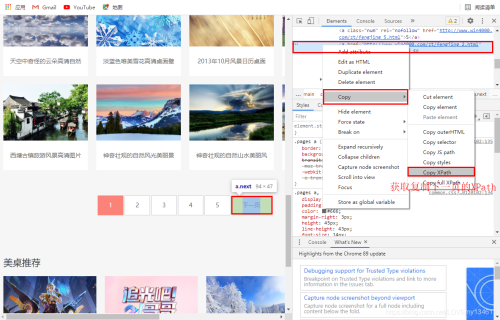
# 查看“下一页”的XPath # /html/body/div[3]/div/div[3]/div[1]/div[2]/div/a[5]
因此可以构建如下XPath:
next_selector = response.xpath('//a[@class="next"]')
点击进入专题,可以看到具体图片,通过查看图片XPath,用于获取图片地址。
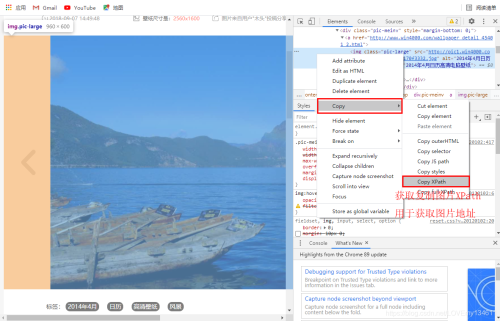
# 构建图片XPath
response.xpath('/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src').extract_first()
可以通过标题和图片序列构建图片名。
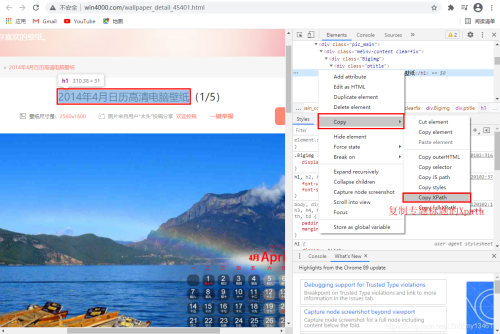
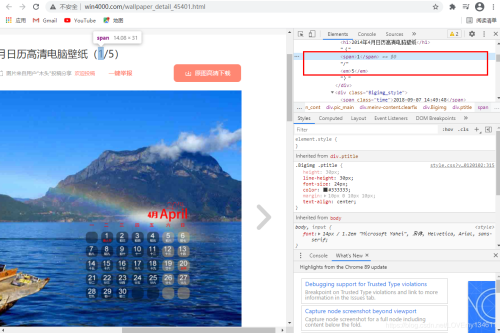
# 利用序号XPath构建图片在列表中的序号
index = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()').extract_first()
# 利用标题XPath构建图片标题
title = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()').extract_first()
# 利用图片标题title和序号index构建图片名
name = title + '_' + index + '.jpg'
同时可以看到,在专题页面下,包含了多张图片,可以通过点击“下一张”按钮来获取下一页面URL,此处为了简化爬取过程,可以通过观察URL规律来构建每一图片详情页的URL,来下载图片。
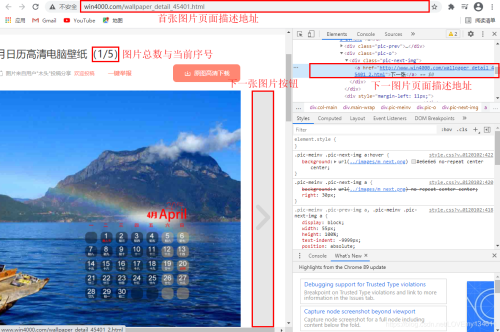
# 第一张图片详情页地址 # http://www.win4000.com/wallpaper_detail_45401.html # 第二张图片详情页地址 # http://www.win4000.com/wallpaper_detail_45401_2.html
因此可以通过首页地址和图片序号来构建每一张图片详情页地址。
# 第一张图片详情页地址
first_url = response.url
# 图片总数
num = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/em/text()').extract_first()
num = int(num)
for i in range(2,num+1):
next_url = '.'.join(first_url.split('.')[:-1]) + '_' + str(i) + '.html'
定义Item字段(Items.py)
本项目用于下载图片,因此可以仅构建图片名和图片地址字段。
# win4000/win4000/items.py
import scrapy
class Win4000Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
name = scrapy.Field()
编写爬虫文件(pictures.py)
代码详解见代码注释。
# win4000/win4000/spiders/pictures.py
import scrapy
from win4000.items import Win4000Item
from urllib import parse
import time
class PicturesSpider(scrapy.Spider):
name = 'pictures'
allowed_domains = ['win4000.com']
start_urls = ['http://www.win4000.com/zt/fengjing.html']
start_urls = ['http://www.win4000.com/zt/fengjing.html']
# cookie用于模仿浏览器行为
cookie={
"t":"29b7c2a8d2bbf060dc7b9ec00e75a0c5",
"r":"7957",
"UM_distinctid":"178c933b40e9-08430036bca215-7e22675c-1fa400-178c933b40fa00",
"CNZZDATA1279564249":"1468742421-1618282415-%7C1618282415",
"XSRF-TOKEN":"eyJpdiI6Ik8rbStsK1Fwem5zR2YzS29ESlI2dmc9PSIsInZhbHVlIjoiaDl5bXp5b1VvWmdSYklWWkEwMWJBK0FaZG9OaDA1VGQ2akZ0RDNISWNDM0hnOW11Q0JTVDZFNlY4cVwvSTBjQlltUG9tMnFUcWd5MzluUVZ0NDBLZlJuRWFuaVF0U3k0XC9CU1dIUzJybkorUEJ3Y2hRZTNcL0JqdjZnWjE5SXFiNm8iLCJtYWMiOiI2OTBjOTkzMTczYWQwNzRiZWY5MWMyY2JkNTQxYjlmZDE2OWUyYmNjNDNhNGYwNDAyYzRmYTk5M2JhNjg5ZmMwIn0%3D",
"win4000_session":"eyJpdiI6Inc2dFprdkdMTHZMSldlMXZ2a1cwWGc9PSIsInZhbHVlIjoiQkZHVlNYWWlET0NyWWlEb2tNS0hDSXAwZGVZV05vTmY0N0ZiaFdTa1VRZUVqWkRmNWJuNGJjNkFNa3pwMWtBcFRleCt4SUFhdDdoYnlPMGRTS0dOR0tkdmVtVDhzUWdTTTc3YXpDb0ZPMjVBVGJzM2NoZzlGa045Qnl0MzRTVUciLCJtYWMiOiI2M2VmMTEyMDkxNTIwNmJjZjViYTg4MjIwZGIxNTlmZWUyMTJlYWZhNjk5ZmM0NzgyMTA3MWE4MjljOWY3NTBiIn0%3D"
}
def start_requests(self):
"""
重构start_requests函数,用于发送带有cookie的请求,模仿浏览器行为
"""
yield scrapy.Request('http://www.win4000.com/zt/fengjing.html', callback=self.parse, cookies=self.cookie)
def parse(self,response):
# 获取下一页的选择器
next_selector = response.xpath('//a[@class="next"]')
for url in next_selector.xpath('@href').extract():
url = parse.urljoin(response.url,url)
# 暂停执行,防止网页的反爬虫程序
time.sleep(3)
# 用于爬取下一页
yield scrapy.Request(url, cookies=self.cookie)
# 用于获取每一专题的选择器
item_selector = response.xpath('/html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li/a/@href')
for item_url in item_selector.extract():
item_url = parse.urljoin(response.url,item_url)
#print(item_url)
time.sleep(3)
# 请求专题页面,并利用回调函数callback解析专题页面
yield scrapy.Request(item_url,callback=self.parse_item, cookies=self.cookie)
def parse_item(self,response):
"""
用于解析专题页面
"""
# 由于Scrapy默认并不会爬取重复页面,
# 因此需要首先构建首张图片实体,然后爬取剩余图片,
# 也可以通过使用参数来取消过滤重复页面的请求
# 首张图片实体
item = Win4000Item()
item['url'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src').extract_first()
index = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()').extract_first()
item['name'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()').extract_first() + '_' + index + '.jpg'
yield item
first_url = response.url
num = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/em/text()').extract_first()
num = int(num)
for i in range(2,num+1):
next_url = '.'.join(first_url.split('.')[:-1]) + '_' + str(i) + '.html'
# 请求其余图片,并用回调函数self.parse_detail解析页面
yield scrapy.Request(next_url,callback=self.parse_detail,cookies=self.cookie)
def parse_detail(self,response):
"""
解析图片详情页面,构建实体
"""
item = Win4000Item()
item['url'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src').extract_first()
index = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()').extract_first()
item['name'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()').extract_first() + '_' + index + '.jpg'
yield item
修改配置文件settings.py
修改win4000/win4000/settings.py中的以下项。
BOT_NAME = 'win4000'
SPIDER_MODULES = ['win4000.spiders']
NEWSPIDER_MODULE = 'win4000.spiders'
# 图片保存文件夹
IMAGES_STORE = './result'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 用于模仿浏览器行为
USER_AGENT = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:87.0) Gecko/20100101 Firefox/87.0'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 下载时延
DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
# 是否启用Cookie
COOKIES_ENABLED = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'win4000.pipelines.Win4000Pipeline': 300,
}
修改管道文件pipelines.py用于下载图片
修改win4000/win4000/pipelines.py文件。
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import os
from scrapy.exceptions import DropItem
class Win4000Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
yield scrapy.Request(url=item['url'],meta={'name':item['name']})
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
with open('img_error_name.txt','a') as f_name:
error_name = str(item['name'])
f_name.write(error_name)
f_name.write('\n')
with open('img_error_url.txt','a') as f_url:
error_url = str(item['url'])
f_url.write(error_url)
f_url.write('\n')
raise DropItem('下载失败')
return item
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None):
# 接收上面meta传递过来的图片名称
filename = request.meta['name']
return filename
编写爬虫启动文件begin.py
在win4000目录下创建begin.py
# win4000/begin.py
from scrapy import cmdline
cmdline.execute('scrapy crawl pictures'.split())
最终目录树
- win4000
- begin.py
- win4000
- spiders
- __init__.py
- pictures.py
- __init__.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
- scrapy.cfg
项目运行
进入begin.py所在目录,运行程序,启动scrapy进行爬虫。
$ python3 begin.py
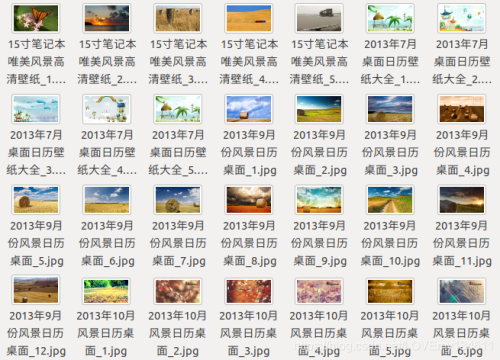
爬取结果
后记
本项目仅用于测试用途。
Enjoy coding.
到此这篇关于Python爬虫之教你利用Scrapy爬取图片的文章就介绍到这了,更多相关python中用Scrapy爬取图片内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



