一、实验目的
(1)熟练使用Counter类进行统计
(2)掌握pandas中的cut方法进行分类
(3)掌握matplotlib第三方库,能熟练使用该三方库库绘制图形
二、实验内容
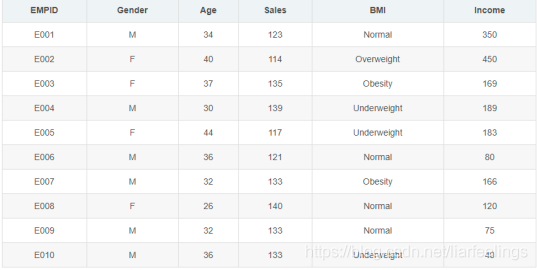
采集到的数据集如下表格所示:
三、实验要求
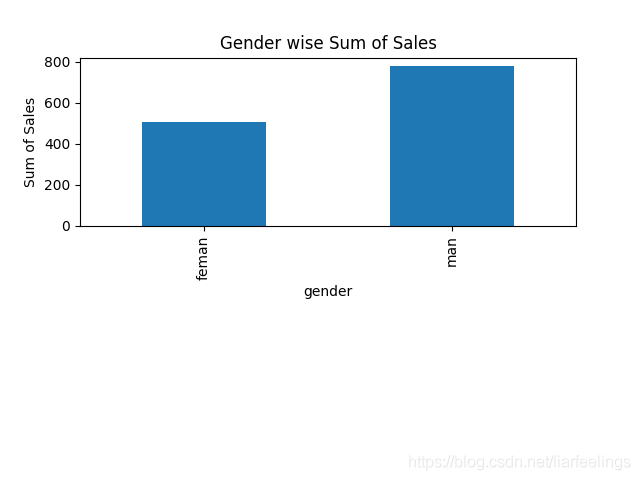
1.按照性别进行分类,然后分别汇总男生和女生总的收入,并用直方图进行展示。
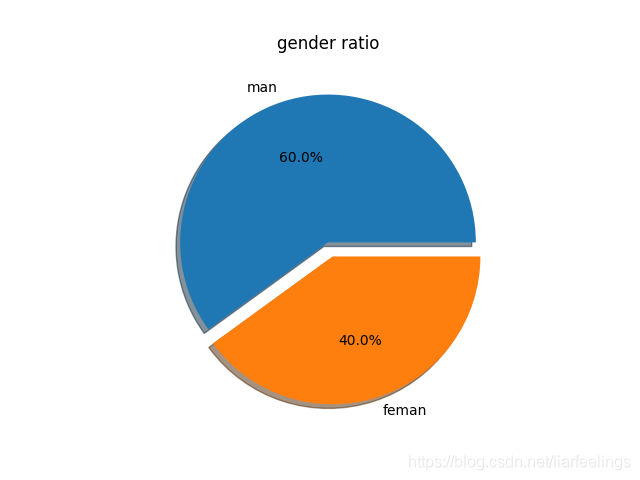
2.男生和女生各占公司总人数的比例,并用扇形图进行展示。
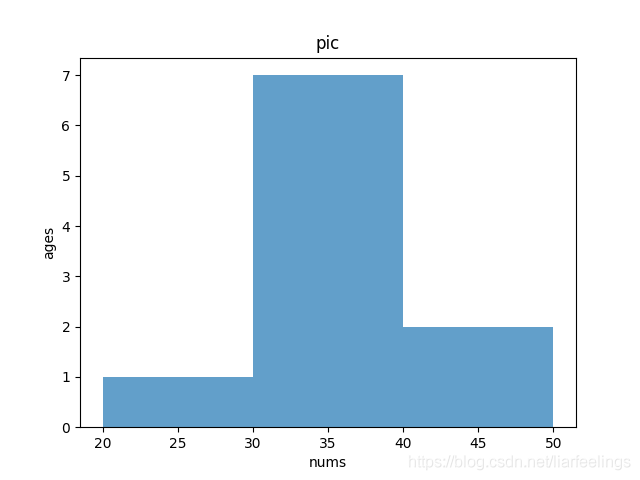
3.按照年龄进行分类(20-29岁,30-39岁,40-49岁),然后统计出各个年龄段有多少人,并用直方图进行展示。
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
info = [{"name": "E001", "gender": "man", "age": "34", "sales": "123", "income": 350},
{"name": "E002", "gender": "feman", "age": "40", "sales": "114", "income": 450},
{"name": "E003", "gender": "feman", "age": "37", "sales": "135", "income": 169},
{"name": "E004", "gender": "man", "age": "30", "sales": "139", "income": 189},
{"name": "E005", "gender": "feman", "age": "44", "sales": "117", "income": 183},
{"name": "E006", "gender": "man", "age": "36", "sales": "121", "income": 80},
{"name": "E007", "gender": "man", "age": "32", "sales": "133", "income": 166},
{"name": "E008", "gender": "feman", "age": "26", "sales": "140", "income": 120},
{"name": "E009", "gender": "man", "age": "32", "sales": "133", "income": 75},
{"name": "E010", "gender": "man", "age": "36", "sales": "133", "income": 40}
]
# 读取数据
def get_data():
df = pd.DataFrame(info)#DataFrame是一个以命名列方式组织的分布式数据集
df[["age"]] = df[["age"]].astype(int) # 数据类型转为int
df[["sales"]] = df[["sales"]].astype(int) # 数据类型转为int
return df
def group_by_gender(df):
var = df.groupby('gender').sales.sum()#groupby将元素通过函数生成相应的Key,数据就转化为Key-Value格式,之后将Key相同的元素分为一组
fig = plt.figure()
ax1 = fig.add_subplot(211)#2*1个网格,1个子图
ax1.set_xlabel('Gender') # x轴标签
ax1.set_ylabel('Sum of Sales') # y轴标签
ax1.set_title('Gender wise Sum of Sales') # 设置图标标题
var.plot(kind='bar')
plt.show() # 显示
def group_by_age(df):
age_list = [20, 30, 40, 50]
res = pd.cut(df['age'], age_list, right=False)
count_res = pd.value_counts(res)
df_count_res = pd.DataFrame(count_res)
print(df_count_res)
plt.hist(df['age'], bins=age_list, alpha=0.7) # age_list 根据年龄段统计
# 显示横轴标签
plt.xlabel("nums")
# 显示纵轴标签
plt.ylabel("ages")
# 显示图标题
plt.title("pic")
plt.show()
def gender_count(df):
res = df['gender'].value_counts()
df_res = pd.DataFrame(res)
label_list = df_res.index
plt.axis('equal')
plt.pie(df_res['gender'], labels=label_list,
autopct='%1.1f%%',
shadow=True, # 设置阴影
explode=[0, 0.1]) # 0 :扇形不分离,0.1:分离0.1单位
plt.title('gender ratio')
plt.show()
print(df_res)
print(label_list)
if __name__ == '__main__':
data = get_data()
group_by_gender(data)
gender_count(data)
group_by_age(data)
到此这篇关于python数据分析之员工个人信息可视化的文章就介绍到这了,更多相关python员工信息可视化内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



