今天在使用pytorch进行训练,在运行 loss.backward() 误差反向传播时出错 :
RuntimeError: grad can be implicitly created only for scalar outputs
File "train.py", line 143, in train
loss.backward()
File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", line 198, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py", line 94, in backward
grad_tensors = _make_grads(tensors, grad_tensors)
File "/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py", line 35, in _make_grads
raise RuntimeError("grad can be implicitly created only for scalar outputs")
RuntimeError: grad can be implicitly created only for scalar outputs
问题分析:
因为我们在执行 loss.backward() 时没带参数,这与 loss.backward(torch.Tensor(1.0)) 是相同的,参数默认就是一个标量。
但是由于自己的loss不是一个标量,而是二维的张量,所以就会报错。
解决办法:
1. 给 loss.backward() 指定传递给后向的参数维度:
loss = criterion(pred, targets) loss.backward() # 改为: loss = criterion(pred, targets) loss.backward(loss.clone().detach())
2. 修改loss函数的输出维度
把张量的输出修改为标量,比如说多多个维度的loss求和或求均值等。此方法对于某些任务不一定适用,可以尝试自己修改。
criterion = nn.L1Loss(reduction='none') # 把参数去掉,改为: criterion = nn.L1Loss()
这里顺便介绍一下pytorch loss函数里面 的reduction 参数
在新的pytorch版本里,使用reduction 参数取代了旧版本的size_average和reduce参数。
reduction 参数有三种选择:
'elementwise_mean':为默认情况,表明对N个样本的loss进行求平均之后返回(相当于reduce=True,size_average=True);
'sum':指对n个样本的loss求和(相当于reduce=True,size_average=False);
'none':表示直接返回n分样本的loss(相当于reduce=False)
补充:在Pytorch下,由于反向传播设置错误导致 loss不下降的原因及解决方案
在Pytorch下,由于反向传播设置错误导致 loss不下降的原因及解决方案
刚刚接触深度学习一段时间,一直在研究计算机视觉方面,现在也在尝试实现自己的idea,从中也遇见了一些问题,这次就专门写一下,自己由于在反向传播(backward)过程中参数没有设置好,而导致的loss不下降的原因。
对于多个网络交替
描述
简单描述一下我的网络结构,我的网络是有上下两路,先对第一路网络进行训练,使用groud truth对这一路的结果进行监督loss_steam1,得到训练好的feature.然后再将得到的feature级联到第二路,通过网络得到最后的结果,再用groud truth进行监督loss。
整个网络基于VGG19网络,在pytorch下搭建,有GPU环境:
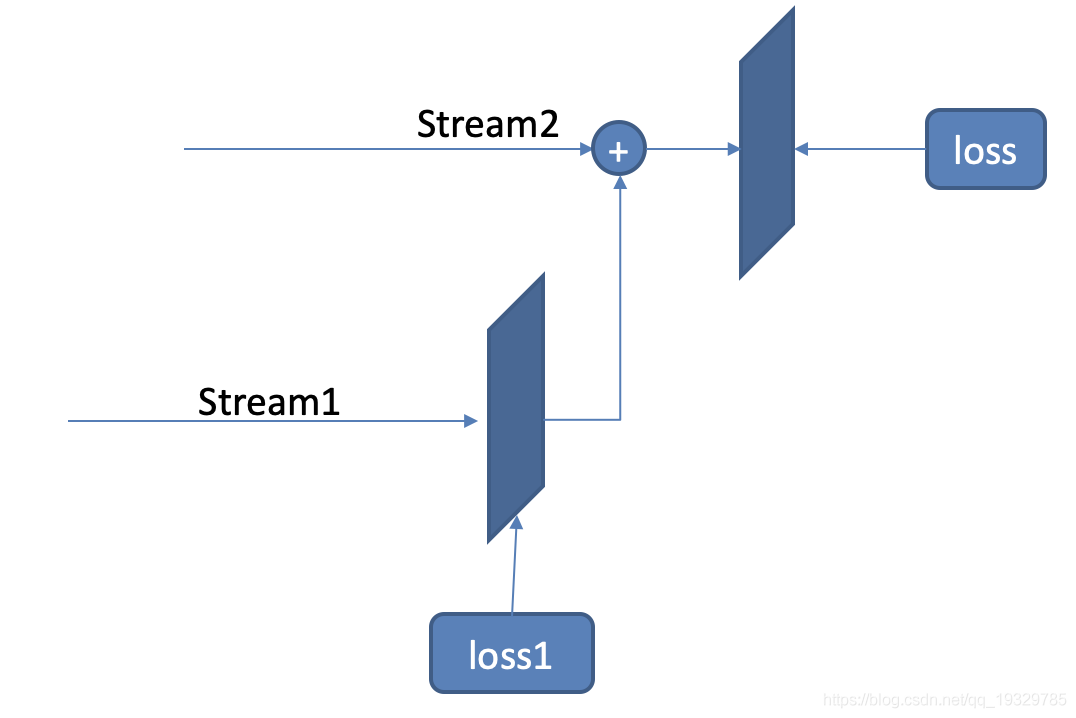
出现的情况,loss_steam1不怎么下降
这个问题确实折麽自己一段时间,结果发现自己出现了一个问题,下面将对这个问题进行分析和解答:
PyTorch梯度传递
在PyTorch中,传入网络计算的数据类型必须是Variable类型, Variable包装了一个Tensor,并且保存着梯度和创建这个Variablefunction的引用,换句话说,就是记录网络每层的梯度和网络图,可以实现梯度的反向传递.
则根据最后得到的loss可以逐步递归的求其每层的梯度,并实现权重更新。
在实现梯度反向传递时主要需要三步:
1、初始化梯度值:net.zero_grad() 清除网络状态
2、反向求解梯度:loss.backward() 反向传播求梯度
3、更新参数:optimizer.step() 更新参数
解决方案
自己在写代码的时候,还是没有对自己的代码搞明白。在反向求解梯度时,对第一路没有进行反向传播,这样肯定不能使这一路的更新,所以我就又加了一步:
loss_steam1.backward( retain_graph = True) //因为每次运行一次backward时,如果不加retain_graph = True,运行完后,计算图都会free掉。
loss.backward()
这样就够了么?我当时也是这么认为的结果发现loss_steam1还是没有降,又愁了好久,结果发现梯度有了,不更新参数,怎么可能有用!
optimizer_steam1.step() //这项必须加 optimizer.step()
哈哈!这样就完成了,效果也确实比以前好了很多。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。



