一、初始化Counter
Counter支持3种形式的初始化,比如提供一个数组,一个字典,或单独键值对“=”式赋值。具体初始化的代码如下所示:
import collections
a = collections.Counter(['a', 'a', 'b', 'b', 'b', 'c'])
b = collections.Counter({"a": 2, "b": 3, "c": 1})
c = collections.Counter(a=2, b=3, c=1)
print(a)
print(b)
print(c)
运行之后,效果如下:
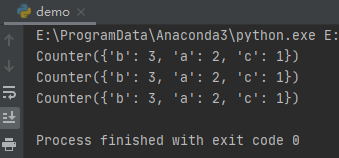
这种是直接通过构造函数进行填充。当然,我们还可以直接构造一个空Counter,然后通过update()函数进行填充。
import collections a = collections.Counter() a.update(['a', 'a', 'b', 'b', 'b', 'c']) print(a)
运行效果和上面的a一样,这里就不上图了,感兴趣的读者自己测试运行。
二、遍历Counter
通过上面初始化以及更新,我们Counter容器中存在了很多的值。因为输出的是字典的形式,所以我们可以直接通过字典的方式进行访问。
import collections
a = collections.Counter()
a.update(['a', 'a', 'b', 'b', 'b', 'c'])
for key in 'abcde':
print(key, "=", a[key])
运行之后,效果如下:
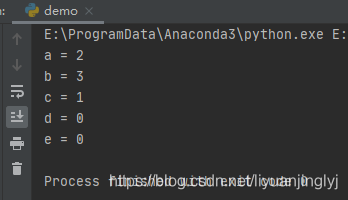
可以看到容器Counter,可以输出空值不报错。因为当我们没有找到某个值时,其默认计数为0。
三、elements()
当然,如果你想实现那种输出没有0值的遍历。可以使用elements()迭代器。具体代码如下:
import collections
a = collections.Counter()
a.update('caabbbc')
print(list(a.elements()))
运行之后,效果如下:
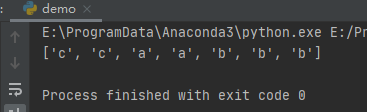
需要注意的是,elements()虽然去除了0值,但并不能保证遍历顺序。
四、most_common
most_common()函数可以生成一个序列,统计包含n个最长遇到的输入值以及相应的计数。这里,我们来实现统计一个文档中,字母出现的个数。具体代码如下:
import collections
c = collections.Counter()
with open('英文文档.txt', 'rt') as f:
for line in f:
c.update(line.rstrip().lower())
for letter, count in c.most_common(5):
print("{}:{}".format(letter, count))
运行之后,效果如下:
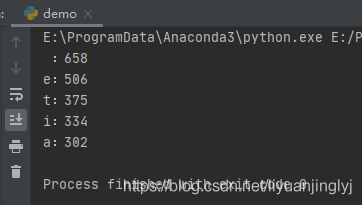
这里统计的英文文档中,空格最多,达到了658个。其他的一次都是前几最多的个数。这样我们可以通过Counter生成一个英文文档中字母的频度分布,在自然语言的处理当中。就可以完美的结合起来进行统计使用。
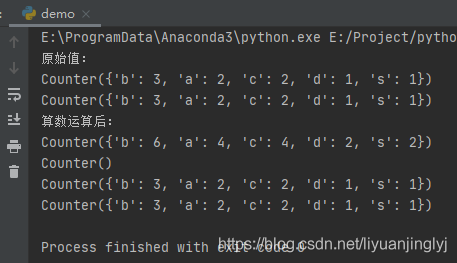
五、算数操作
Counter容器不仅可以统计频度的分布。还可以进行一些算数运算。比如将两个Counter容器进行相加进行统计,亦或者相减也行。具体操作如下:
import collections
c1 = collections.Counter('abcbcabds')
c2 = collections.Counter('abcbcabds')
print("原始值:")
print(c1)
print(c2)
print("算数运算后:")
print(c1 + c2)
print(c1 - c2)
print(c1 & c2)
print(c1 | c2)
运行之后,效果如下:
到此这篇关于Python统计可散列的对象之容器Counter详解的文章就介绍到这了,更多相关Python容器Counter内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



