Pytorch反向传播计算梯度默认累加
今天学习pytorch实现简单的线性回归,发现了pytorch的反向传播时计算梯度采用的累加机制, 于是百度来一下,好多博客都说了累加机制,但是好多都没有说明这个累加机制到底会有啥影响, 所以我趁着自己练习的一个例子正好直观的看一下以及如何解决:
pytorch实现线性回归
先附上试验代码来感受一下:
torch.manual_seed(6)
lr = 0.01 # 学习率
result = []
# 创建训练数据
x = torch.rand(20, 1) * 10
y = 2 * x + (5 + torch.randn(20, 1))
# 构建线性回归函数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True)
# 这里是迭代过程,为了看pytorch的反向传播计算梯度的细节,我先迭代两次
for iteration in range(2):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# 反向传播
loss.backward()
# 这里看一下反向传播计算的梯度
print("w.grad:", w.grad)
print("b.grad:", b.grad)
# 更新参数
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
上面的代码比较简单,迭代了两次, 看一下计算的梯度结果:
w.grad: tensor([-74.6261])
b.grad: tensor([-12.5532])
w.grad: tensor([-122.9075])
b.grad: tensor([-20.9364])
然后我稍微加两行代码, 就是在反向传播上面,我手动添加梯度清零操作的代码,再感受一下结果:
torch.manual_seed(6)
lr = 0.01
result = []
# 创建训练数据
x = torch.rand(20, 1) * 10
#print(x)
y = 2 * x + (5 + torch.randn(20, 1))
#print(y)
# 构建线性回归函数
w = torch.randn((1), requires_grad=True)
#print(w)
b = torch.zeros((1), requires_grad=True)
#print(b)
for iteration in range(2):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# 由于pytorch反向传播中,梯度是累加的,所以如果不想先前的梯度影响当前梯度的计算,需要手动清0
if iteration > 0:
w.grad.data.zero_()
b.grad.data.zero_()
# 反向传播
loss.backward()
# 看一下梯度
print("w.grad:", w.grad)
print("b.grad:", b.grad)
# 更新参数
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
w.grad: tensor([-74.6261])
b.grad: tensor([-12.5532])
w.grad: tensor([-48.2813])
b.grad: tensor([-8.3831])
从上面可以发现,pytorch在反向传播的时候,确实是默认累加上了上一次求的梯度, 如果不想让上一次的梯度影响自己本次梯度计算的话,需要手动的清零。
但是, 如果不进行手动清零的话,会有什么后果呢? 我在这次线性回归试验中,遇到的后果就是loss值反复的震荡不收敛。下面感受一下:
torch.manual_seed(6)
lr = 0.01
result = []
# 创建训练数据
x = torch.rand(20, 1) * 10
#print(x)
y = 2 * x + (5 + torch.randn(20, 1))
#print(y)
# 构建线性回归函数
w = torch.randn((1), requires_grad=True)
#print(w)
b = torch.zeros((1), requires_grad=True)
#print(b)
for iteration in range(1000):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# print("iteration {}: loss {}".format(iteration, loss))
result.append(loss)
# 由于pytorch反向传播中,梯度是累加的,所以如果不想先前的梯度影响当前梯度的计算,需要手动清0
#if iteration > 0:
# w.grad.data.zero_()
# b.grad.data.zero_()
# 反向传播
loss.backward()
# 更新参数
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
if loss.data.numpy() < 1:
break
plt.plot(result)
上面的代码中,我没有进行手动清零,迭代1000次, 把每一次的loss放到来result中, 然后画出图像,感受一下结果:
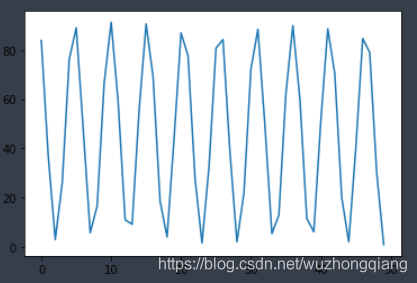
接下来,我把手动清零的注释打开,进行每次迭代之后的手动清零操作,得到的结果:
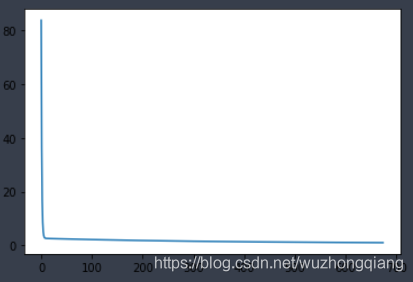
可以看到,这个才是理想中的反向传播求导,然后更新参数后得到的loss值的变化。
总结
这次主要是记录一下,pytorch在进行反向传播计算梯度的时候的累加机制到底是什么样子? 至于为什么采用这种机制,我也搜了一下,大部分给出的结果是这样子的:

但是如果不想累加的话,可以采用手动清零的方式,只需要在每次迭代时加上即可
w.grad.data.zero_() b.grad.data.zero_()
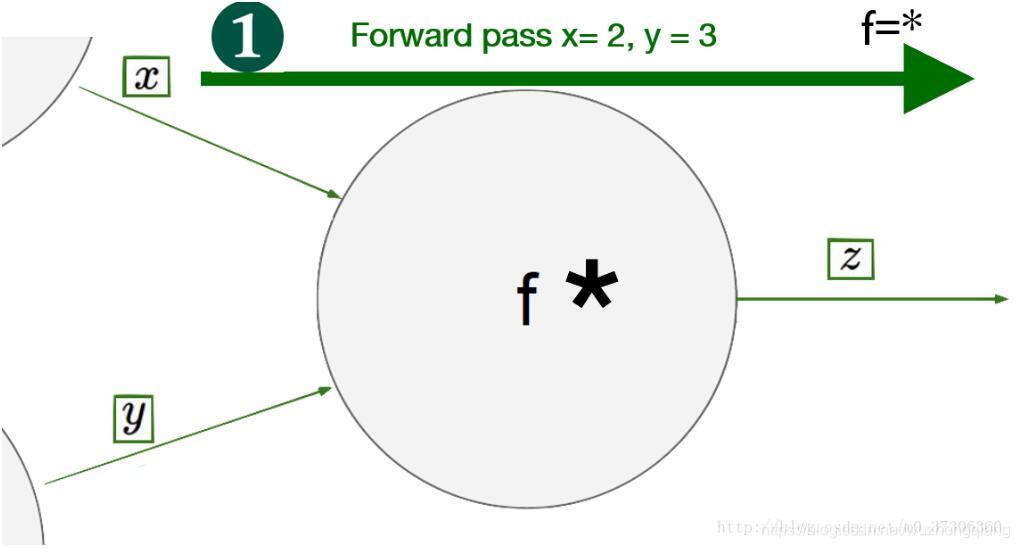
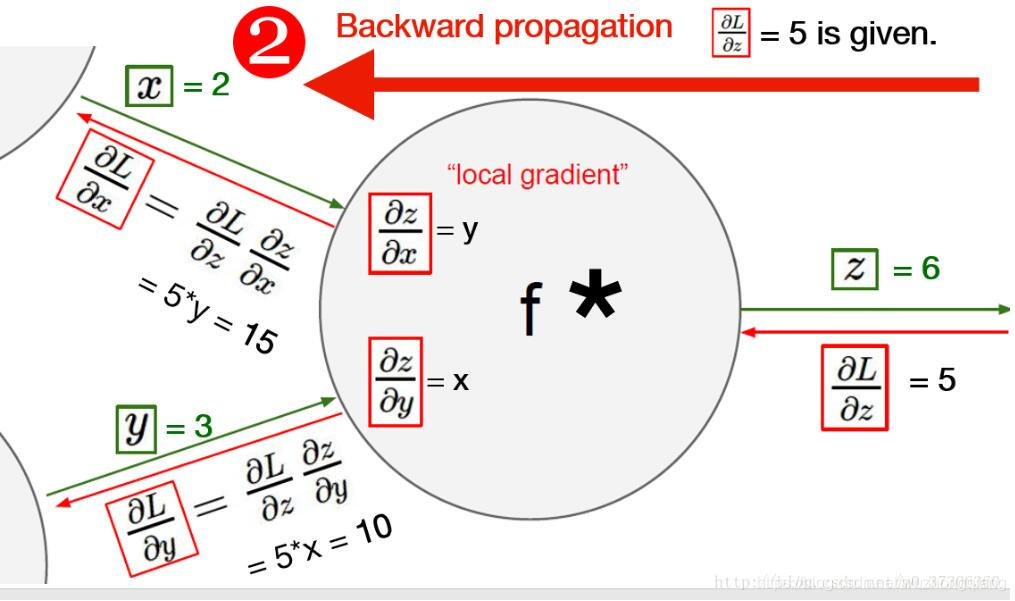
另外, 在搜索资料的时候,在一篇博客上看到两个不错的线性回归时pytorch的计算图在这里借用一下:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。



