一、项目需求
爬取排行榜小说的作者,书名,分类以及完结或连载
二、项目分析
目标url:“https://www.qidian.com/rank/hotsales?style=1&page=1”

通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低。

通过控制台观察发现,需要的内容都在一个个li列表中,每一个列表代表一本书的内容。
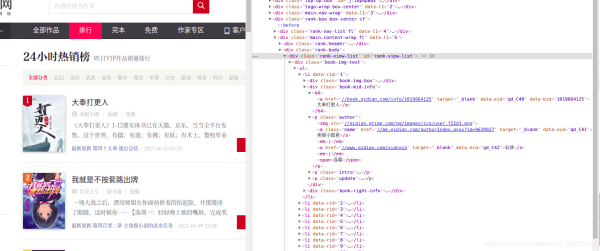
在li中找到所需的内容

找到第两页的url
“https://www.qidian.com/rank/hotsales?style=1&page=1”
“https://www.qidian.com/rank/hotsales?style=1&page=2”
对比找到页数变化
开始编写scrapy程序。
三、程序编写
创建项目太简单,不说了
1.编写item(数据存储)
import scrapy
class QidianHotItem(scrapy.Item):
name = scrapy.Field() #名称
author = scrapy.Field() #作者
type = scrapy.Field() #类型
form= scrapy.Field() #是否完载
2.编写spider(数据抓取(核心代码))
#coding:utf-8
from scrapy import Request
from scrapy.spiders import Spider
from ..items import QidianHotItem
#导入下需要的库
class HotSalesSpider(Spider):#设置spider的类
name = "hot" #爬虫的名称
qidian_header={"user-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"} #设置header
current_page = 1 #爬虫起始页
def start_requests(self): #重写第一次请求
url="https://www.qidian.com/rank/hotsales?style=1&page=1"
yield Request(url,headers=self.qidian_header,callback=self.hot_parse)
#Request发起链接请求
#url:目标url
#header:设置头部(模拟浏览器)
#callback:设置页面抓起方式(空默认为parse)
def hot_parse(self, response):#数据解析
#xpath定位
list_selector=response.xpath("//div[@class='book-mid-info']")
#获取所有小说
for one_selector in list_selector:
#获取小说信息
name=one_selector.xpath("h4/a/text()").extract()[0]
#获取作者
author=one_selector.xpath("p[1]/a[1]/text()").extract()[0]
#获取类型
type=one_selector.xpath("p[1]/a[2]/text()").extract()[0]
# 获取形式
form=one_selector.xpath("p[1]/span/text()").extract()[0]
item = QidianHotItem()
#生产存储器,进行信息存储
item['name'] = name
item['author'] = author
item['type'] = type
item['form'] = form
yield item #送出信息
# 获取下一页URL,并生成一个request请求
self.current_page += 1
if self.current_page <= 10:#爬取前10页
next_url = "https://www.qidian.com/rank/hotsales?style=1&page="+str(self.current_page)
yield Request(url=next_url,headers=self.qidian_header,callback=self.hot_parse)
def css_parse(self,response):
#css定位
list_selector = response.css("[class='book-mid-info']")
for one_selector in list_selector:
# 获取小说信息
name = one_selector.css("h4>a::text").extract()[0]
# 获取作者
author = one_selector.css(".author a::text").extract()[0]
# 获取类型
type = one_selector.css(".author a::text").extract()[1]
# 获取形式
form = one_selector.css(".author span::text").extract()[0]
# 定义字典
item=QidianHotItem()
item['name']=name
item['author'] = author
item['type'] = type
item['form'] = form
yield item
3.start.py(代替命令行)
在爬虫项目文件夹下创建start.py。

from scrapy import cmdline
#导入cmd命令窗口
cmdline.execute("scrapy crawl hot -o hot.csv" .split())
#运行爬虫并生产csv文件
出现类似的过程代表爬取成功。
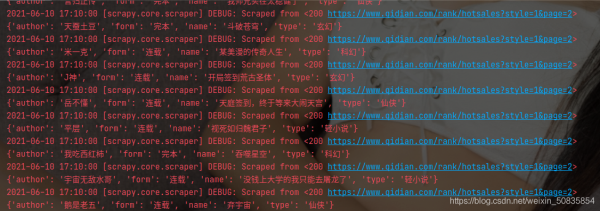
hot.csv
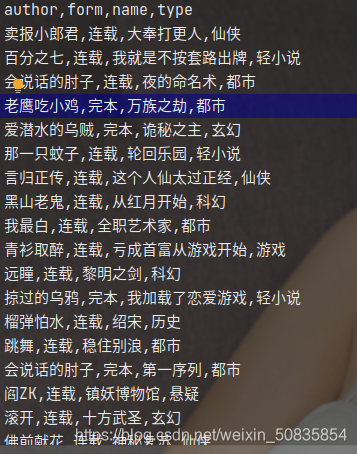
总结
本次爬虫内容还是十分简单的因为只用了spider和item,这几乎是所有scrapy都必须调用的文件,后期还会有middlewarse.py,pipelines.py,setting.py需要编写和配置,以及从javascript和json中提取数据,难度较大。
到此这篇关于Python scrapy爬取起点中文网小说榜单的文章就介绍到这了,更多相关Python爬取起点中文网内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!



